スケジュール管理ツールを公開します
Google Code Archive - Long-term storage for Google Code Project Hosting.
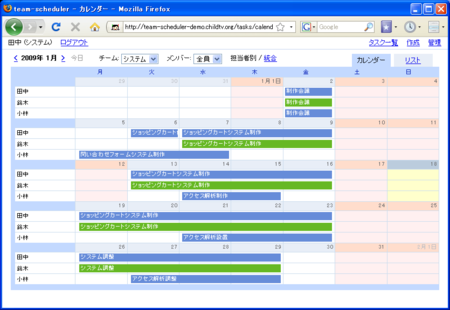
動作デモ
知り合いの会社にこういうのほしいなーと言われて作ったスケジュール管理のシステムを公開します。渡して終わりにするのもなんなので。カレンダーに書き込むだけのシンプル操作、という感じです。革新的な機能や技術的に面白い所は特にありません。
きょうのほのぼの日記

今日はおかあさんから届いた荷物の中身を紹介します。

志満秀の海老なかよし。おかあさんの姉夫婦の家に毎年届くのだけど食べる人がいないのでいつも僕のところまでまわってくる、とのことです。えびがまるごと入った、なかなか庶民には口にできなそうな高級感あふれるおせんべです。おいしい。

大量のいかめし。ごはんを炊くのも面倒だし外に食べに行く気力もない、というときに重宝します。パックのいかめしは普通に買うと結構値が張るのですが、マルエツの従業員であるおかあさんの前では正規の価格など意味を成しません。

人形焼です。僕はカステラっぽいもの全般がすきなのです。一緒に入っていた普通のカステラはもう食べました。

レンジでできるリゾット。あたらしもの好きなので面白がって食べるだろう、というもくろみだと思われます。お茶の間のCM感がします。

駄目になっているから廃棄するように電話で言われました。荷物と入れ違いで年末に実家に帰ってしまったのですよね。

千葉の名産落花生。甘味と香ばしさがあってそこそこの豆な感じがします、が最近落花生は食べていないので鑑定舌に自信はありません。
あとは似たようなおかしやおかず多数。いつも荷物を送った後に確認の電話をくれるのだけど、携帯電話の充電器が壊れていたりマナーモードで気付かなかったりで1週間くらい返事をしないでいたら、なにかあったんじゃないかと心配した、おとうさんに僕の部屋まで様子を見に行くように頼もうかと考えていた、と言われた。そんな大げさな、息子さんもいい歳なのに、と口では言いつつも、ちょっと嬉しかったりする、と書けばきれいに良い話という感じだけど、嬉しいかどうかはよくわからない。嫌だってことはないけど。おかあさんが死んだらなにか思うだろうか。小学校2年生のときにおじいちゃんが死んで、まわりが泣いているときにぼさっとしていたらあきちゃんのおばさんに、だいくんは小さいから人が死ぬってことがわからないのね、と言われて、わかってないのかーそうかーと思ったのを覚えているんだけど、あれからあまり変わっていない気がする。こんな事書いてると怒られるかな。ちいさいころ人の生き死にの話をするとおかあさんにそんな話するなって厳しく言われてたからね。だから浜ちゃんが死ね死ね言うダウンタウンの番組なんてみてたら絶対に怒られると思って、ガキの使いのある日は姉と2人で寝たふりをして、番組が始まる頃こっそり起きて、薄暗い中スピーカーに耳をあててくすくす笑ってた。今ではジャンクSPORTS始まるから8に変えてよとおかあさんが言ってるんだけど。
以上ほのぼの日記でした。
きょうの日記
今日は祝日だと先週末に教えてもらった。いつも祝日と知らずに出社して、ふにゃーっとなっているので。今後のためにRainlendarというデスクトップカレンダーを入れてiCalの祝日データをインポートした。祝日がイベント扱いなので土日と表示色が違ってちょっときになる。スキンをいじろうとしたらバイナリファイルだったのでまあいいやということにした。
だらだらとゲームでもしてようと思って近所のツタヤで幻想水滸伝 公式ポータルウェブサイト|KONAMIを買ったら、これが失敗した。思えばレジで初回特典のドラマCDを渡されたところでもう嫌な予感がしたのだ。お正月に実家で世界樹の迷宮をやって楽しかったので似たようなゲームがやりたくて選んだのだけど、FFっぽいというのだろうか、紙芝居の間にキャラクターを動かすRPGという感じで、まあそれはそれでいいんだけど、「やってみなきゃわかんねぇだろ!」が口癖の主人公の少年と仲間たちの語らいがつらい。
主人公「で、その話にオチはあるの?」
幼馴染「なにいってんのよ!」
一同「はははは」
僕「勘弁してくれ」
という具合で。もぎたてチンクルにすればよかった。
そういうわけで、なにしよう。ブックマークのエントリーに全コメントしよう。http://b.hatena.ne.jp/entrylist?url=http://d.hatena.ne.jp/&threshold=3 から。
- classList、relList - 素人がプログラミングを勉強するブログ
- 複数クラス名をjavascriptから扱うのは気が引ける、というのはありますよね。そこらへんはブラウザが面倒を見てくれるようになる、ようです。
- いましろたかしが好きなやつはセンスがない - ハックルベリーに会いに行く
- 増田に書け。いや書かないで。冗談です。このエントリ自体がいましろたかしの作風をもとにひねったネタだったりするのでしょうか。
- グエボスの少女のはなし - 続・Cinema, the Jury 映画が掟だ! はてな死闘編
- ファ文関連。挑戦せねばなるまい。んー。女の子が降ってくるのはばれているから、それを逆手にとってですね、なにかの破片がぽたぽた空から降ってきて、読者がああこの破片が合体して少女になる前に弾を打ち込んで撃破するとボーナス点だなと思ったところを、なにかこう。んー。
- 戦艦大和は沖縄を本気で守るために出撃した、と宣伝する小学校教師 - 土曜の夜、牛と吼える。青瓢箪。
- わんわん
- フェルクリンゲン、高いところは足下すかすか - 鳥よ!
- にゃーにゃー
あきらめた。おふろはいる。
HBase InputFormat/OutputFormat for Hadoop Streaming
What is this?
InputFormat/OutputFormat to use HBase tables as input/output of MapReduce in Hadoop Streaming.
Usage
debian:~% hadoop dfs -mkdir dammy_input
debian:~% hadoop jar hadoop-streaming.jar \
-input dammy_input \
-output output \
-mapper /bin/cat \
-inputformat org.childtv.hadoop.hbase.mapred.JSONTableInputFormat \
-jobconf map.input.table=scores \
-jobconf map.input.columns=course:
debian:~% hadoop dfs -cat output/*
Dan {"course:math":"87","course:art":"97"}
Dana {"course:math":"100","course:art":"80"}
Setting
Supported Options
- -jobconf map.input.table=
- Input table name for the Map step
- -jobconf map.input.columns=
- Column name to scan. Separate by whitespace for multi columns
- -jobconf map.input.binary=
- Optional. Input column names and cell values are Base64 encoded if true
- -jobconf map.input.timestamp=
- Optional. Timestamps are added to input if true
- -jobconf reduce.output.table=
- Output table name
- -jobconf reduce.output.binary=
- Set true when column names and cell values are Base64 encoded
InputFormats
org.childtv.hadoop.hbase.mapred.JSONTableInputFormat
Dan {"course:math":"87","course:art":"97"}-inputformat=json -jobconf map.input.timestamp=true
Dan {"course:math":{"value":"87","timestamp":"1226501804191"},"course:art":{"value":"97","timestamp":"1226501810087"}}
org.childtv.hadoop.hbase.mapred.XMLTableInputFormat
Same format as REST API GET /[table_name]/row/[row_key]/
Dan <?xml version="1.0" encoding="UTF-8"?><row><column><name>course:art</name><value>97</value></column><column><name>course:math</name><value>87</value></column></row>
Values are also same when add option -jobconf map.input.binary=true
Dan <?xml version="1.0" encoding="UTF-8"?><row><column><name>Y291cnNlOmFydA==</name><value>OTc=</value></column><column><name>Y291cnNlOm1hdGg=</name><value>ODc=</value></column></row>
org.childtv.hadoop.hbase.mapred.ListTableInputFormat
Only values of cell separated by whitespace.
Dan 97 87
You can change separator.
-inputformat=list -jobconf map.input.value.separator=,
Dan 97,87
custom format
Implement a subclass of org.childtv.hadoop.hbase.mapred.TextTableInputFormat
OutputFormats
Read comments on sources.
hadoop-hbase-streaming を更新しました
前のエントリーをマニュアルっぽく更新
http://d.hatena.ne.jp/wanpark/20081112/1226504022
変更点
- オプションのパースのバグ修正
- inputformat に xml, list を追加
- inputformat のオプションを追加
今後の予定
- output でテーブルに書き出す
その他
Thrift っていうのを使えば普通に他の言語から扱えるの?よく知らない
追記
InputFormat だけあればいいんじゃないですか、確かにそうですね、ということで InputFormat だけにした。
追記
OutputFormat も書いた。飽きてきたのでソース読めってことにしとく。
HBase 入門 (2)
Hadoop の MapReduce で HBase を使ってみましょう。
1. セットアップ
$HADOOP_HOME/conf/hadoop-env.sh の HADOOP_CLASSPATH に HBase のパスを加えます。
export HADOOP_CLASSPATH=$HBASE_HOME/hbase-0.2.1.jar:$HBASE_HOME/conf
前回のプログラムで動作確認。
debian:~/tmp/hbase% jar cf hbase-basic.jar HBaseBasic.class debian:~/tmp/hbase% $HADOOP_HOME/bin/hadoop jar hbase-basic.jar HBaseBasic
前回通りに動けばOKです。
2. MapReduce を理解する
http://hadoop.apache.org/core/docs/r0.17.2/mapred_tutorial.html を読むのがよいと思います。また検索すれば多くの情報がみつかります。Example: WordCount v1.0 が理解できればまあいいでしょう。
3. 簡単な例
前回同様 http://www.nabble.com/Re%3A-Map-Reduce-over-HBase---sample-code-p18253120.html を参考にします。大体同じようなコードですが、バージョンに合わせて修正したりしています。
scores テーブル
| grade: | course:math | course:art | |
|---|---|---|---|
| Dan | 1 | 87 | 97 |
| Dana | 2 | 100 | 80 |
この成績表から、各科目の平均点を計算します。
courses テーブル
| stats:average | |
|---|---|
| math | 93.5 |
| art | 88.5 |
hbase(main):001:0> create 'scores', 'grade', 'course' 0 row(s) in 6.3180 seconds hbase(main):002:0> create 'courses', 'stats' 0 row(s) in 7.8030 seconds
import java.io.IOException; import java.io.ByteArrayOutputStream; import java.io.DataOutputStream; import java.io.ByteArrayInputStream; import java.io.DataInputStream; import java.util.Map; import java.util.Iterator; import org.apache.hadoop.io.Text; import org.apache.hadoop.io.Writable; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.FloatWritable; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.mapred.JobClient; import org.apache.hadoop.mapred.JobConf; import org.apache.hadoop.mapred.OutputCollector; import org.apache.hadoop.mapred.Reporter; import org.apache.hadoop.hbase.io.BatchUpdate; import org.apache.hadoop.hbase.io.RowResult; import org.apache.hadoop.hbase.io.Cell; import org.apache.hadoop.hbase.io.ImmutableBytesWritable; import org.apache.hadoop.hbase.mapred.TableMap; import org.apache.hadoop.hbase.mapred.TableReduce; import org.apache.hadoop.hbase.util.Writables; public class StatsScore extends Configured implements Tool { // Sara {math:62, art:45} -> {math, 62}, {art, 45}, public static class StatsMap extends TableMap<Text, IntWritable> { public void map(ImmutableBytesWritable key, RowResult value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { for (Map.Entry<byte[], Cell> entry : value.entrySet()) { Text course = new Text(new String(entry.getKey()).split(":", 2)[1]); IntWritable score = new IntWritable(); Writables.copyWritable(entry.getValue().getValue(), score); output.collect(course, score); } } } // {math, {62, 45, 87}} -> {math, 65.6} public static class StatsReduce extends TableReduce<Text, IntWritable> { public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<ImmutableBytesWritable, BatchUpdate> output, Reporter reporter) throws IOException { int size = 0; int sum = 0; while (values.hasNext()) { size++; sum += values.next().get(); } float average = (float)sum / (float)size; BatchUpdate bu = new BatchUpdate(key.getBytes()); bu.put("stats:average", Writables.getBytes(new FloatWritable(average))); output.collect(new ImmutableBytesWritable(key.getBytes()), bu); } } public int run(String[] args) throws Exception { JobConf conf = new JobConf(getConf(), this.getClass()); conf.setJobName("compute average scores"); TableMap.initJob("scores", "course:", StatsMap.class, Text.class, IntWritable.class, conf); TableReduce.initJob("courses", StatsReduce.class, conf); JobClient.runJob(conf); return 0; } public static void main(String [] args) throws Exception { ToolRunner.run(new Configuration(), new StatsScore(), args); } }
実行。
debian:~/tmp/hbase% javac -d classes StatsScore.java debian:~/tmp/hbase% jar cf stats-score.jar classes debian:~/tmp/hbase% $HADOOP_HOME/bin/hadoop jar stats-score.jar StatsScore
結果はてきとうに確認してください。
データの処理の流れは次のようになっています。
scores テーブル
↓
Dan { course:math => 87, course:art => 97 }
↓ map()
(math, 87), (art, 97)
↓
(math, [87, 100])
↓ reduce()
(math, 93.5)
↓
couses テーブル重要なのは map 関数と reduce 関数です。それぞれ TableMap, TableReduce のサブクラスで定義されています。
TableMap を使うと、テーブル内の全ての row を走査して map に渡すことができます。HTable から map するときは大抵使うことになるでしょう。動作の設定は TableMap.initJob で行います。第2引数では取得したいカラム名をスペース区切りの文字列で渡していて、この場合は scores テーブルの course: カラムファミリーを含む RowResult が map に渡されます。
map の値を reduce で集計、という部分は普通の MapReduce と変わりません。
TableReduce は、output に BatchUpdate を渡すと、TableReduce.initJob で指定したテーブルにコミットしてくれるようになります。テーブルのインスタンスを管理しなくていい、程度のありがたみです。
両 initJob で各種設定を済ませてくれるので、conf.setInputFormat() などを手動で設定する必要はありません。
次回はもうすこし規模の大きい実践的なプログラムをみて、理解を深めます。
Hadoop Streaming で HBase を使う
HBase のテーブルを Hadoop Streaming の入出力にするための InputFormat/OutputFormat を書きました。
GitHub - wanpark/hadoop-hbase-streaming: HBase InputFormat/OutputFormat for Hadoop Streaming
例
debian:~% hadoop dfs -mkdir dammy_input
debian:~% hadoop jar hadoop-streaming.jar \
-input dammy_input \
-output output \
-mapper /bin/cat \
-inputformat org.childtv.hadoop.hbase.mapred.JSONTableInputFormat \
-jobconf map.input.table=scores \
-jobconf map.input.columns=course:
debian:~% hadoop dfs -cat output/*
Dan {"course:math":"87","course:art":"97"}
Dana {"course:math":"100","course:art":"80"}
使い方
コマンドオプション
input format の説明
org.childtv.hadoop.hbase.mapred.JSONTableInputFormat
Dan {"course:math":"87","course:art":"97"}-jobconf map.input.timestamp=true だと構造が変わります。
Dan {"course:math":{"value":"87","timestamp":"1226501804191"},"course:art":{"value":"97","timestamp":"1226501810087"}}
org.childtv.hadoop.hbase.mapred.XMLTableInputFormat
REST API の GET /[table_name]/row/[row_key]/ と同形式の XML を出力します。
Dan <?xml version="1.0" encoding="UTF-8"?><row><column><name>course:art</name><value>97</value></column><column><name>course:math</name><value>87</value></column></row>
-jobconf map.input.binary=true にすると、中身の値も REST API と同じになります。
Dan <?xml version="1.0" encoding="UTF-8"?><row><column><name>Y291cnNlOmFydA==</name><value>OTc=</value></column><column><name>Y291cnNlOm1hdGg=</name><value>ODc=</value></column></row>
org.childtv.hadoop.hbase.mapred.ListTableInputFormat
cell の値のみを空白で区切って出力します。
Dan 97 87
-jobconf map.input.value.separator=
-jobconf map.input.value.separator=,
Dan 97,87
独自のフォーマット
org.childtv.hadoop.hbase.mapred.TextTableInputFormat のサブクラスを実装します。簡単です。
output format の説明
ソースのコメントを読んでください